Kwalifikacja: INF.02 - Administracja i eksploatacja systemów komputerowych, urządzeń peryferyjnych i lokalnych sieci komputerowych
Zawód: Technik informatyk
Kategorie: Sieci komputerowe Bezpieczeństwo i kopie zapasowe Licencje i oprogramowanie
Na dołączonym obrazku pokazano działanie
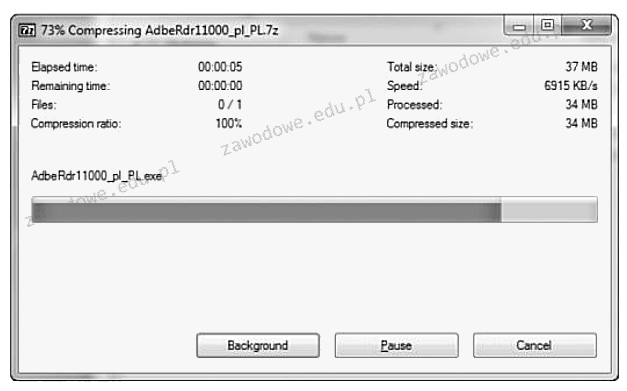
Odpowiedzi
Informacja zwrotna
Kompresja danych to proces redukcji rozmiaru plików poprzez usuwanie redundancji w danych. Jest to kluczowy etap w zarządzaniu wielkimi zbiorami danych oraz w transmisji danych przez sieci, szczególnie gdy przepustowość jest ograniczona. Najczęściej stosowane algorytmy kompresji to ZIP RAR i 7z, które różnią się efektywnością i czasem kompresji. Kompresja jest szeroko stosowana w różnych dziedzinach techniki i informatyki, m.in. przy przesyłaniu plików w Internecie, gdzie ograniczenie wielkości plików przyspiesza ich przepływ. Proces ten jest również istotny w przechowywaniu danych, ponieważ zredukowane pliki zajmują mniej miejsca na dyskach twardych, co przyczynia się do oszczędności przestrzeni dyskowej oraz kosztów związanych z utrzymaniem infrastruktury IT. Przy kompresji plików istotne jest zachowanie integralności danych, co zapewniają nowoczesne algorytmy kompresji bezstratnej, które umożliwiają odtworzenie oryginalnych danych bez żadnych strat. Kompresja ma również zastosowanie w multimediach, gdzie algorytmy stratne są używane do zmniejszenia rozmiarów plików wideo i audio poprzez usuwanie mniej istotnych danych, co jest mniej zauważalne dla ludzkiego oka i ucha.