Kwalifikacja: INF.02 - Administracja i eksploatacja systemów komputerowych, urządzeń peryferyjnych i lokalnych sieci komputerowych
Zawód: Technik informatyk
Kategorie: Sieci komputerowe Bezpieczeństwo i kopie zapasowe Podstawy informatyki
Na dołączonym obrazku ukazano proces
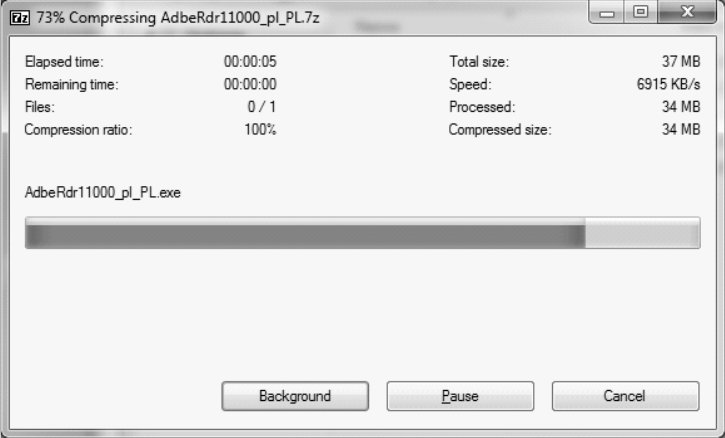
Odpowiedzi
Informacja zwrotna
Kompresja danych to proces polegający na zmniejszaniu objętości danych poprzez zastosowanie algorytmów, które eliminują zbędne informacje lub optymalizują ich strukturę. Na załączonym obrazku widzimy interfejs programu 7-Zip, który jest jednym z popularniejszych narzędzi służących do kompresji plików. Proces ten ma na celu zwiększenie efektywności przechowywania i przesyłania danych, co jest szczególnie istotne w przypadku dużych plików lub ograniczonej przestrzeni dyskowej. Kompresja może być stratna lub bezstratna; w przypadku zastosowań, gdzie istotne jest zachowanie integralności danych, najczęściej wybiera się metody bezstratne. W kontekście standardów branżowych, formaty takie jak ZIP, RAR czy 7Z są powszechnie stosowane i wspierane przez większość systemów operacyjnych. Praktyczne zastosowania kompresji danych obejmują archiwizację, redukcję kosztów transferu danych oraz szybsze ładowanie stron internetowych. Kluczowym aspektem jest również znajomość różnicy między metodami kompresji i umiejętność wyboru odpowiedniej w zależności od potrzeb i ograniczeń technologicznych. Dobre praktyki w tej dziedzinie obejmują regularne aktualizowanie narzędzi kompresji oraz świadomość potencjalnych zagrożeń związanych z dekompresją podejrzanych lub nieznanych plików. Kompresja danych odgrywa istotną rolę w informatyce i telekomunikacji, będąc nieodłącznym elementem optymalizacji przepływu informacji.