Kwalifikacja: INF.03 - Tworzenie i administrowanie stronami i aplikacjami internetowymi oraz bazami danych
Zawód: Technik informatyk , Technik programista
Kategorie: Bazy danych
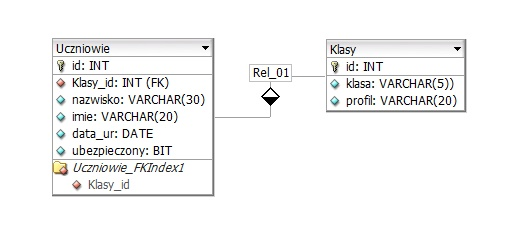
Dodanie ograniczenia klucza obcego w taki sposób, aby kolumna Klasy_id z tabeli Uczniowie była powiązana z kolumną id w tabeli Klasy zostanie wykonane przy użyciu polecenia
Odpowiedzi
Informacja zwrotna
Poprawnie wskazana składnia polecenia `ALTER TABLE Uczniowie ADD CONSTRAINT FKKlasy FOREIGN KEY(Klasy_id) REFERENCES Klasy(id);` dokładnie odpowiada temu, co chcemy osiągnąć: dodać ograniczenie klucza obcego do już istniejącej tabeli. W SQL (np. w standardowym podejściu stosowanym w SQL Server, Oracle, wielu innych systemach) dodawanie klucza obcego odbywa się właśnie przez `ALTER TABLE ... ADD CONSTRAINT ... FOREIGN KEY ... REFERENCES ...`. Najpierw wskazujemy modyfikowaną tabelę (`Uczniowie`), potem nazwę nowego ograniczenia (`FKKlasy`), następnie kolumnę w tabeli podrzędnej (`Klasy_id`), a na końcu tabelę oraz kolumnę, do której się odwołujemy (`Klasy(id)`). Dzięki temu silnik bazy danych wie, że każda wartość w `Uczniowie.Klasy_id` musi mieć odpowiadający rekord w `Klasy.id`. To jest właśnie istota referencyjnej integralności danych. W praktyce takie powiązanie uniemożliwia np. dopisanie ucznia do nieistniejącej klasy albo usunięcie klasy, do której nadal przypisani są uczniowie (chyba że jawnie zdefiniujemy `ON DELETE CASCADE` czy inne zachowanie). Moim zdaniem warto też zwracać uwagę na nazewnictwo: prefiks `FK` w nazwie ograniczenia (`FKKlasy`) to dobra praktyka, bo od razu widać, że to klucz obcy, a nie np. unikalny indeks. W większych projektach przyjęcie spójnej konwencji, typu `FK_Uczniowie_Klasy`, bardzo ułatwia debugowanie błędów i analizę schematu. W codziennej pracy z bazami danych takie polecenie wykorzystuje się często po wczytaniu danych testowych albo po przebudowie tabel, gdy chcemy najpierw stworzyć strukturę bez ograniczeń, a potem krok po kroku dokładać klucze główne i obce. Warto też pamiętać, że przed dodaniem klucza obcego kolumna `Klasy_id` powinna mieć ten sam lub kompatybilny typ co `Klasy.id` (np. oba `INT`) i nie może zawierać wartości, które nie istnieją w tabeli `Klasy`, bo wtedy polecenie zakończy się błędem i klucz obcy nie zostanie utworzony.