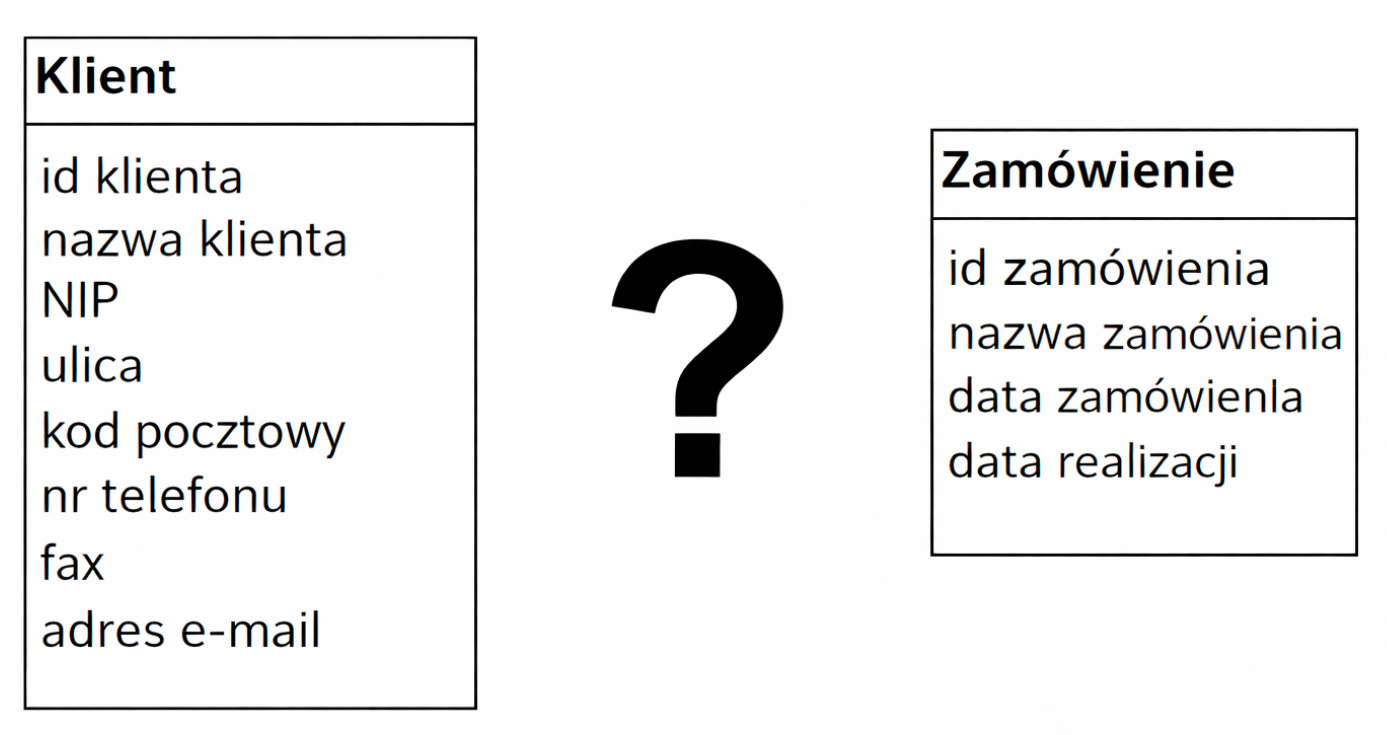
Poprawnie wskazana relacja 1:n (jeden do wielu), gdzie „1” jest po stronie tabeli Klient, a „n” po stronie tabeli Zamówienie, dokładnie odzwierciedla opisany przypadek biznesowy: jeden klient sklepu internetowego może złożyć wiele zamówień, a każde zamówienie należy do jednego, konkretnego klienta. W praktyce projektowania relacyjnych baz danych oznacza to, że w tabeli Zamówienie umieszczamy klucz obcy (np. kolumnę id_klienta), który wskazuje na klucz główny w tabeli Klient (np. id_klienta jako PRIMARY KEY). To jest klasyczny przykład relacji nadrzędny–podrzędny (parent–child). Z mojego doświadczenia w systemach e‑commerce taka struktura jest standardem, bo pozwala łatwo wykonywać typowe kwerendy: wyszukiwanie wszystkich zamówień danego klienta, liczenie wartości zamówień na klienta, analizę historii zakupów. Dodatkowo założenie, że każdy klient dokona co najmniej dwóch zamówień, wpływa na tzw. krotność minimalną po stronie Zamówienia (min 2), ale nie zmienia samego typu relacji – nadal jest to 1:n. W modelu logicznym i fizycznym realizujemy to przez odpowiednie więzy integralności: klucz główny w tabeli Klient i klucz obcy w tabeli Zamówienie z ON DELETE RESTRICT lub CASCADE (w zależności od polityki biznesowej). Taka relacja ułatwia normalizację danych: dane klienta trzymamy w jednym miejscu, unikamy duplikacji w wielu zamówieniach, a w razie zmiany np. adresu e‑mail aktualizujemy tylko jeden rekord. W dobrze zaprojektowanych schematach (np. zgodnych z 3NF) dokładnie tak modeluje się powiązanie Klient–Zamówienie.
W tym zadaniu pułapka polega głównie na poprawnym zrozumieniu biznesowego sensu relacji. Opis mówi jasno, że mamy tabelę Klient i tabelę Zamówienie w sklepie internetowym oraz że każdy klient złoży co najmniej dwa zamówienia. To automatycznie sugeruje relację, w której pojedynczy klient jest powiązany z wieloma zamówieniami, ale każde konkretne zamówienie należy tylko do jednego klienta. Relacja 1:1 między Klientem a Zamówieniem byłaby sensowna wtedy, gdyby na jednego klienta przypadało dokładnie jedno zamówienie. W praktyce systemów sprzedażowych to bardzo rzadki przypadek i raczej zły model. Prowadziłby do sytuacji, że dla kolejnego zamówienia tego samego klienta trzeba by tworzyć nowy rekord klienta, czyli duplikować dane osobowe, adres, NIP itd. To łamie podstawowe zasady normalizacji (szczególnie pierwszą i trzecią postać normalną) i bardzo utrudnia późniejsze raportowanie. Relacja n:n sugeruje, że jedno zamówienie mogłoby należeć do wielu klientów, a jeden klient do wielu zamówień jednocześnie, przy czym do poprawnego odwzorowania takiej relacji trzeba by wprowadzić tabelę pośredniczącą, np. Klient_Zamówienie. W kontekście sklepu internetowego takie założenie jest nielogiczne: jedno zamówienie ma jednego właściciela, nie ma sensu aby ten sam koszyk zakupowy był przypisany do kilku różnych klientów. Relacja n:n jest typowa raczej dla powiązań typu Produkt–Zamówienie (wiele produktów w wielu zamówieniach), a nie Klient–Zamówienie. Z kolei relacja 1:n odwrócona, gdzie „1” jest po stronie Zamówienia, a „n” po stronie Klienta, oznaczałaby, że jedno zamówienie może być przypisane do wielu klientów. To dokładnie odwrócenie poprawnego modelu i w praktyce niewykonalne biznesowo – kto byłby płatnikiem, kto odbiorcą, jak liczyć historię zakupów? Taki projekt łamie też zasadę jednoznacznej odpowiedzialności rekordu: zamówienie powinno mieć jednego, jasno określonego właściciela. Typowym błędem myślowym przy takich pytaniach jest mylenie relacji Klient–Zamówienie z relacją Zamówienie–Produkt. Tam rzeczywiście często stosuje się n:n z tabelą pośrednią (pozycje zamówienia). Warto zawsze zatrzymać się i odpowiedzieć sobie na proste pytanie: czy ten obiekt może realnie „należeć” do więcej niż jednego innego obiektu? W przypadku zamówienia odpowiedź brzmi: nie, dlatego poprawnym podejściem jest właśnie relacja 1:n z jednym klientem i wieloma jego zamówieniami.