Kwalifikacja: INF.03 - Tworzenie i administrowanie stronami i aplikacjami internetowymi oraz bazami danych
Zawód: Technik informatyk , Technik programista
Kategorie: Bazy danych
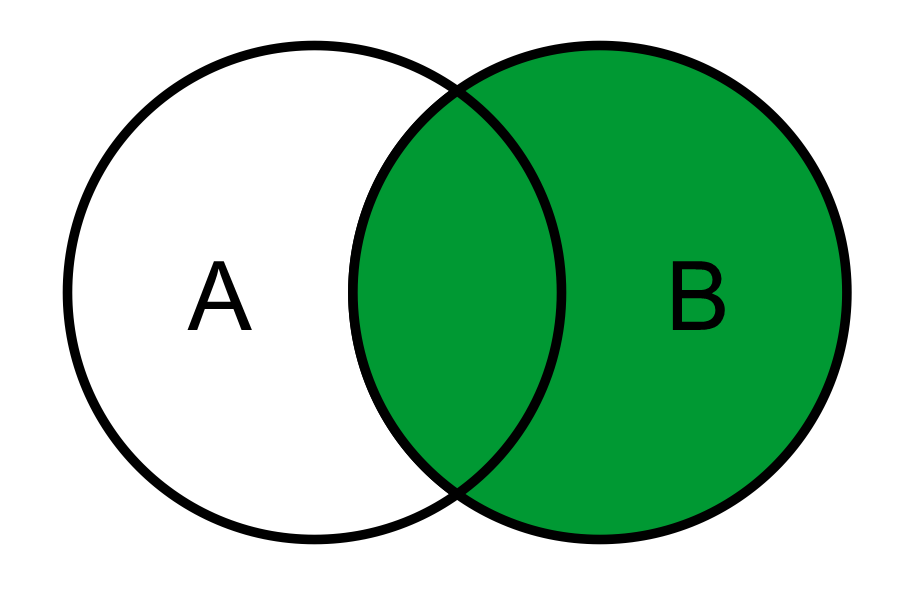
W języku SQL, aby wybrać wszystkie rekordy z tabeli B, w tym część wspólną z tabelą A, należy zastosować typ związku
Odpowiedzi
Informacja zwrotna
Poprawnie – w tym zadaniu kluczowe jest zrozumienie, że interesuje nas **wszystko z tabeli B**, a dodatkowo – tam gdzie się da – dokładamy dane z tabeli A. Dokładnie tak działa `RIGHT JOIN` zapisany jako `A RIGHT JOIN B ON ...`. Prawa tabela w zapisie JOIN (czyli B) jest zawsze tą „obowiązkową”: dostajemy wszystkie jej wiersze, a dane z lewej (A) pojawiają się tylko tam, gdzie warunek łączenia jest spełniony. Tam gdzie dopasowania w A nie ma, kolumny z A przyjmują wartość `NULL`. To dokładnie odpowiada zielonemu obszarowi na diagramie – cała B plus część wspólna A∩B. W praktyce taki RIGHT JOIN przydaje się np. gdy tabela B jest tabelą główną (np. `Zamowienia`), a tabela A jest pomocnicza (np. `Klienci_archiwalni`), ale z jakiegoś powodu w zapytaniu chcemy właśnie B mieć „gwarantowaną” – czyli nawet jeśli w A brakuje powiązanego rekordu, zamówienie i tak ma się pojawić w wynikach. Przykładowo: `SELECT * FROM Klienci_archiwalni A RIGHT JOIN Zamowienia B ON A.id_klienta = B.id_klienta;` Dobra praktyka w SQL mówi, że częściej stosuje się `LEFT JOIN`, bo jest czytelniejszy (łatwiej myśleć: „biorę wszystko z lewej”), ale logicznie RIGHT JOIN robi to samo, tylko „odwraca perspektywę”. Wiele zespołów wręcz zaleca, żeby zamiast RIGHT JOIN przepisać zapytanie tak, by użyć LEFT JOIN i zamienić kolejność tabel – ale na egzaminach i w testach warto znać oba. Moim zdaniem dobrze jest też od razu kojarzyć: `LEFT JOIN` – wszystko z lewej, `RIGHT JOIN` – wszystko z prawej, `INNER JOIN` – tylko przecięcie, `FULL OUTER JOIN` – suma zbiorów. Dzięki temu każde zadanie z diagramem Venna w SQL robi się dużo prostsze i mniej mylące.