Kwalifikacja: INF.03 - Tworzenie i administrowanie stronami i aplikacjami internetowymi oraz bazami danych
Zawód: Technik informatyk , Technik programista
Kategorie: Bazy danych
W przedstawionym diagramie bazy danych biblioteka, elementy: czytelnik, wypozyczenie i ksiazka są
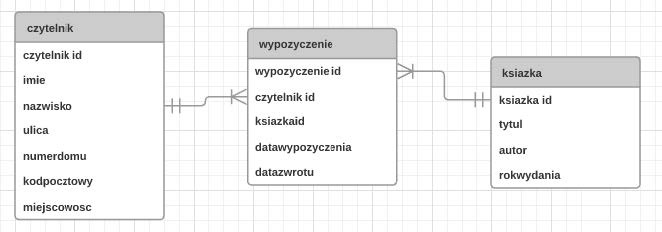
Odpowiedzi
Informacja zwrotna
W diagramie bazy danych pokazanym w pytaniu elementy „czytelnik”, „wypozyczenie” i „ksiazka” to klasyczne przykłady encji. Encja w modelu relacyjnym (a dokładniej w modelu ER – Entity-Relationship) oznacza pewien typ obiektu ze świata rzeczywistego, o którym chcemy przechowywać dane w bazie. W praktyce encja odpowiada tabeli w relacyjnej bazie danych: encja CZYTELNIK → tabela czytelnik, encja KSIĄŻKA → tabela ksiazka, encja WYPOŻYCZENIE → tabela wypozyczenie. Każda z tych encji ma swój klucz główny (np. czytelnik_id, ksiazka_id, wypozyczenie_id), czyli atrybut jednoznacznie identyfikujący rekord. To jest dokładnie to, co w dobrych praktykach projektowania baz danych (np. wg standardowych metodologii ERD używanych w SQL Server, MySQL Workbench czy Oracle Data Modeler) uważa się za podstawę poprawnego modelu danych. Moim zdaniem bardzo ważne jest rozróżnienie poziomów: encja to „typ obiektu” (tabela), atrybut to „cecha obiektu” (kolumna), a krotka/rekord to „konkretne wystąpienie obiektu” (pojedynczy wiersz). Na przykład: encja CZYTELNIK opisuje wszystkich możliwych czytelników biblioteki, atrybuty tej encji to imie, nazwisko, ulica itd., a jedna konkretna krotka w tabeli czytelnik opisuje jedną osobę, np. Jana Kowalskiego z ulicy Lipowej 5. W projektowaniu systemów bibliotecznych, systemów sprzedażowych, magazynowych czy w aplikacjach webowych z bazą danych zawsze zaczyna się właśnie od zidentyfikowania encji: klient, zamówienie, produkt, faktura itd. Dopiero potem dopisuje się atrybuty, ustala relacje (tak jak tu: czytelnik – wypożyczenie – książka) i definiuje klucze obce. To podejście jest zgodne z normalizacją i ogólnymi zasadami projektowania relacyjnych baz danych – pomaga uniknąć nadmiarowości danych i błędów logicznych w aplikacji.