Kwalifikacja: INF.03 - Tworzenie i administrowanie stronami i aplikacjami internetowymi oraz bazami danych
Zawód: Technik informatyk , Technik programista
Kategorie: Tworzenie stron WWW
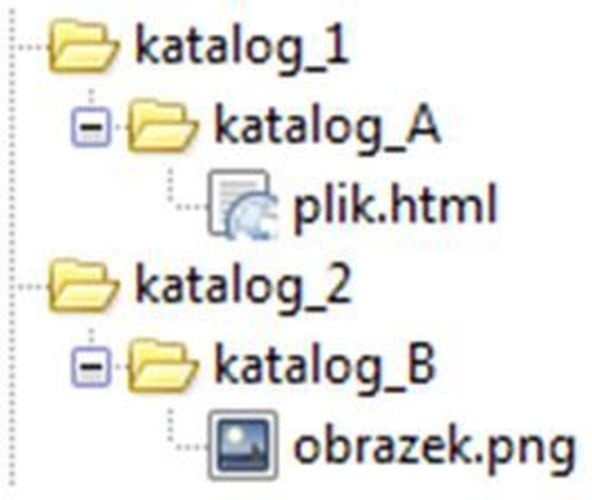
Wskaż, który zapis należy zastosować w celu wyświetlenia grafiki obrazek.png na stronie WWW w pliku plik.html.
Odpowiedzi
Informacja zwrotna
Poprawny zapis <img src="../../katalog_2/katalog_B/obrazek.png"> wynika bezpośrednio z położenia pliku HTML i grafiki w strukturze katalogów. plik.html znajduje się w katalogu_1/katalog_A, a obrazek.png w katalogu_2/katalog_B. Żeby przeglądarka mogła odnaleźć plik graficzny, ścieżka względna musi krok po kroku „przejść” po tej strukturze. Najpierw ../../ cofa nas dwa poziomy w górę: z katalog_A do katalog_1, a potem z katalog_1 do katalogu głównego, w którym znajdują się katalog_1 i katalog_2. Następnie wchodzimy do katalog_2, potem do katalog_B i dopiero tam leży obrazek.png. To dokładnie odzwierciedla poprawną, relatywną drogę od pliku HTML do zasobu graficznego. Z mojego doświadczenia w projektach webowych używanie poprawnych ścieżek względnych jest kluczowe, szczególnie gdy serwis ma rozbudowaną strukturę folderów albo jest później przenoszony między środowiskami (np. localhost, serwer testowy, produkcja). Dzięki ścieżkom względnym, takim jak ../../katalog_2/katalog_B/obrazek.png, kod HTML jest bardziej przenośny i nie trzeba modyfikować adresów po każdej zmianie domeny czy katalogu głównego. Warto też pamiętać, że atrybut src w znaczniku <img> zawsze wskazuje na zasób, który przeglądarka ma pobrać – może to być ścieżka względna, bezwzględna w obrębie serwera lub pełny URL z protokołem. W praktyce przy większych projektach dobrze jest utrzymywać spójną konwencję nazewnictwa katalogów (np. img, assets, static) i stosować logiczną strukturę, żeby takie ścieżki były łatwe do ogarnięcia. Moim zdaniem warto też na wczesnym etapie przyzwyczaić się do „ręcznego” analizowania, skąd jest liczona ścieżka – zawsze od lokalizacji aktualnego dokumentu HTML, chyba że używamy ścieżek absolutnych od katalogu głównego serwera.