Kwalifikacja: INF.03 - Tworzenie i administrowanie stronami i aplikacjami internetowymi oraz bazami danych
Zawód: Technik informatyk , Technik programista
Kategorie: Bazy danych Administracja serwerem i bezpieczeństwo
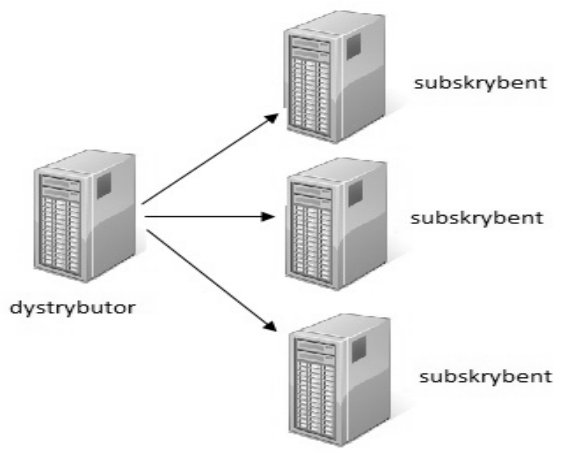
Model fizyczny replikacji bazy danych pokazany na ilustracji jest modelem
Odpowiedzi
Informacja zwrotna
Model centralnego wydawcy jest popularnym rozwiązaniem w replikacji baz danych gdzie jeden centralny serwer działa jako główny wydawca danych do wielu subskrybentów. Kluczowa cecha tego modelu polega na tym że wszystkie zmiany są inicjowane na głównym serwerze co pozwala na scentralizowane zarządzanie danymi. Centralny wydawca zapewnia że dane są spójne i aktualizowane we wszystkich subskrybentach zmniejszając ryzyko konfliktów danych. Taka architektura jest często stosowana w organizacjach z rozproszonymi jednostkami gdzie centralny serwer w centrali obsługuje oddziały terenowe. Przykładami zastosowań są systemy ERP i CRM które wymagają jednoczesnej replikacji danych do wielu lokalizacji. Dobre praktyki w tej architekturze obejmują regularne monitorowanie wydajności serwerów oraz optymalizację przepustowości sieci by minimalizować opóźnienia. Modele centralnego wydawcy wykorzystują technologie takie jak SQL Server Replication czy Oracle Streams które są dobrze udokumentowane i szeroko stosowane w branży zapewniając niezawodność i skalowalność.