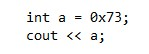Pytanie 1
Który z frameworków pozwala na tworzenie aplikacji z graficznym interfejsem użytkownika oraz obsługą wydarzeń?
A. Express.js
B. TensorFlow
C. Qt
D. Django
Django to framework do tworzenia aplikacji webowych w języku Python, a nie narzędzie do budowy aplikacji desktopowych z interfejsem graficznym. TensorFlow to biblioteka do uczenia maszynowego i sztucznej inteligencji, która nie ma bezpośredniego związku z projektowaniem GUI. Express.js to framework dla Node.js, który służy do budowy aplikacji serwerowych i API, ale nie jest narzędziem do projektowania interfejsów użytkownika w aplikacjach desktopowych.