Pytanie 1
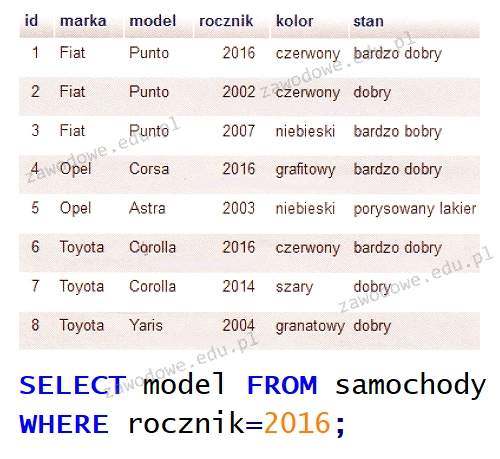
Jakie zapytanie SQL będzie odpowiednie do odnalezienia w podanej tabeli tylko imion oraz nazwisk pacjentów, którzy przyszli na świat przed rokiem 2002?
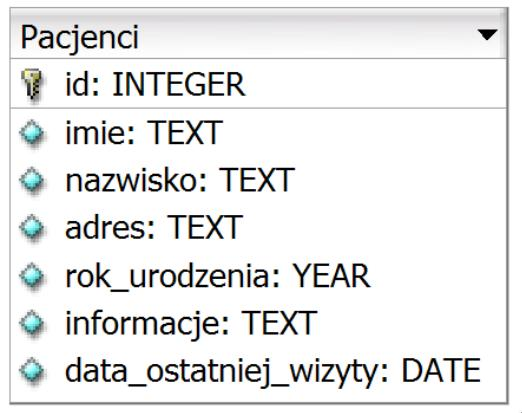
A. SELECT imie, nazwisko FROM Pacjenci WHERE data_ostatniej_wizyty < 2002
B. SELECT imie, nazwisko FROM Pacjenci WHERE rok_urodzenia < 2002
C. SELECT * FROM Pacjenci WHERE rok_urodzenia <= 2002
D. SELECT * FROM Pacjenci WHERE rok_urodzenia LIKE 2002
W SQL naprawdę ważne jest, żeby znać różnice między różnymi operatorami i strukturami. Często można się potknąć na operatorach takich jak LIKE, ponieważ ten operator nadaje się bardziej do tekstów, a nie do porównań liczbowych. Tak naprawdę, w przypadku liczb lepiej używać operatorów takich jak < lub <=, które są bardziej celne i efektywne. Jak porównujesz rok urodzenia z 2002, to którzy się urodzili przed tym rokiem, to operator < jest tu niezbędny. Inną sprawą jest użycie selekcji * – to z kolei pobiera wszystkie dane z tabeli. Oczywiście, rozumiem, że nie zawsze jest to potrzebne, bo i tak interesuje nas tylko kilka kolumn. Poza tym, umiejętność pisania sensownych zapytań to kluczowa umiejętność w pracy z bazami danych. Na koniec, warunek data_ostatniej_wizyty < 2002 jest zupełnie nietrafiony, bo dotyczy wizyt, a nie urodzin pacjentów, co totalnie mija się z celem. Musisz bardziej zwracać uwagę na to, jakie kolumny potrzebujesz, żeby dobrze zrozumieć, co właściwie chcesz wyciągnąć z bazy danych.