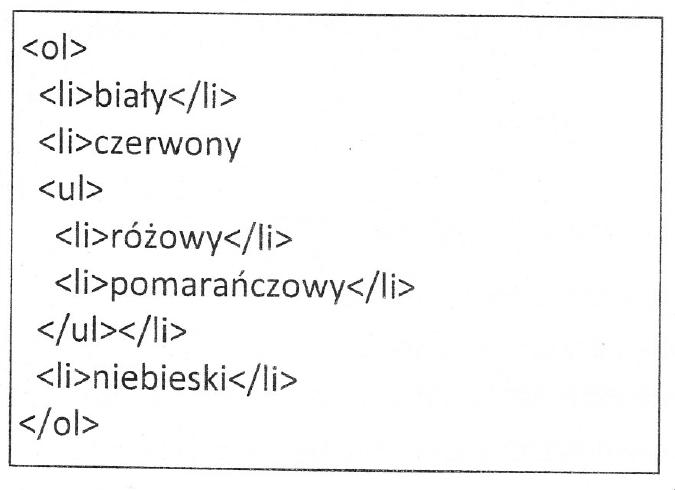
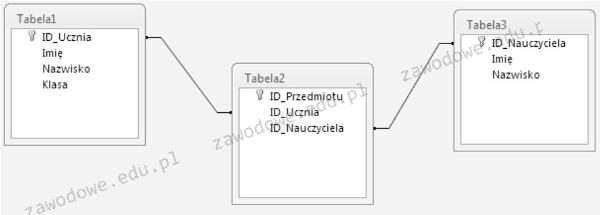
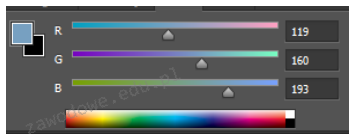
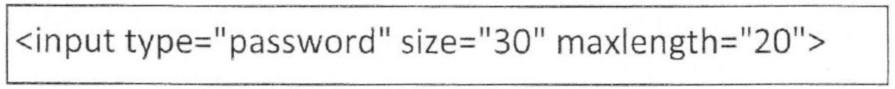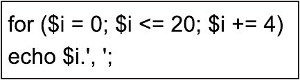Pytanie 1
Wyrażenie JavaScript: document.write(5==='5′); co zostanie wyświetlone?
A. 0
B. false
C. true
D. 1
Odpowiedzi, które wybrałeś, jak '0', 'true' i '1', pokazują, że mogło dojść do pewnych nieporozumień w zrozumieniu, jak działają operatory porównania w JavaScript. Na przykład '0' może sugerować, że sądzisz, że wynik jest liczbowy, a nie logiczny. Warto pamiętać, że w JavaScript liczby i wartości logiczne to różne typy danych. '0' oznacza fałsz, więc to nie jest właściwy wynik. Odpowiedź 'true' świadczy o błędnym przekonaniu, że porównywane wartości są takie same, co nie jest zgodne z tym, co robi '===' . Natomiast odpowiedź '1' sugeruje, że mogłeś pomylić wynik porównania z kodem prawdy w formie 1, co zdarza się w niektórych językach, ale w JavaScript to nie działa. Kluczowe jest to, że '===' porównuje zarówno wartości, jak i typy, więc porównując liczbę i ciąg znaków, dostajemy 'false'. W JavaScript mamy 'true' i 'false', a porównania powinny uwzględniać typy danych, żeby uniknąć zamieszania. Fajnie byłoby, gdybyś zgłębił temat typów danych w JavaScript i sam spróbował różnych porównań, żeby lepiej to ogarnąć.