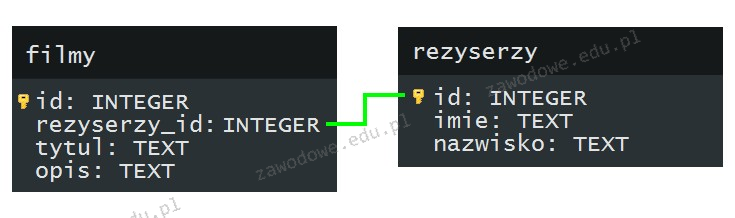
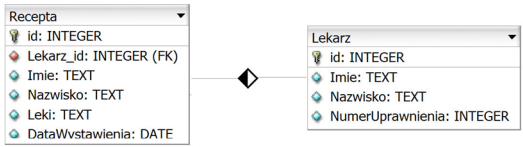
Pytanie 1
Według zasad walidacji HTML5, właściwym zapisem dla znacznika hr jest
A. <hr>
B. </ hr />
C. </hr?>
D. </ hr>
Odpowiedź <hr> jest poprawna, ponieważ zgodnie z regułami HTML5, znacznik <hr> jest znakiem samodzielnym, co oznacza, że nie wymaga zamknięcia. Jest to element blokowy, który służy do wprowadzania poziomej linii w dokumencie, co często wykorzystuje się do rozdzielania sekcji treści. Standard HTML5 zezwala na użycie skróconej formy, a zatem <hr> jest wystarczające do oznaczenia poziomej linii. W praktyce, użycie tego znacznika jest istotne dla strukturyzacji dokumentów i poprawy ich czytelności. Dobrą praktyką jest również stosowanie odpowiednich atrybutów, takich jak 'class' czy 'id', co może ułatwić późniejsze stylizowanie za pomocą CSS. Warto pamiętać, że w HTML5, chociaż można używać atrybutów takich jak 'style' czy 'title', powinny one być stosowane odpowiedzialnie, aby nie zaburzać semantyki dokumentu. Ponadto, korzystanie z tego znacznika jest zgodne z WAI-ARIA, co wspiera dostępność aplikacji webowych.