Pytanie 1
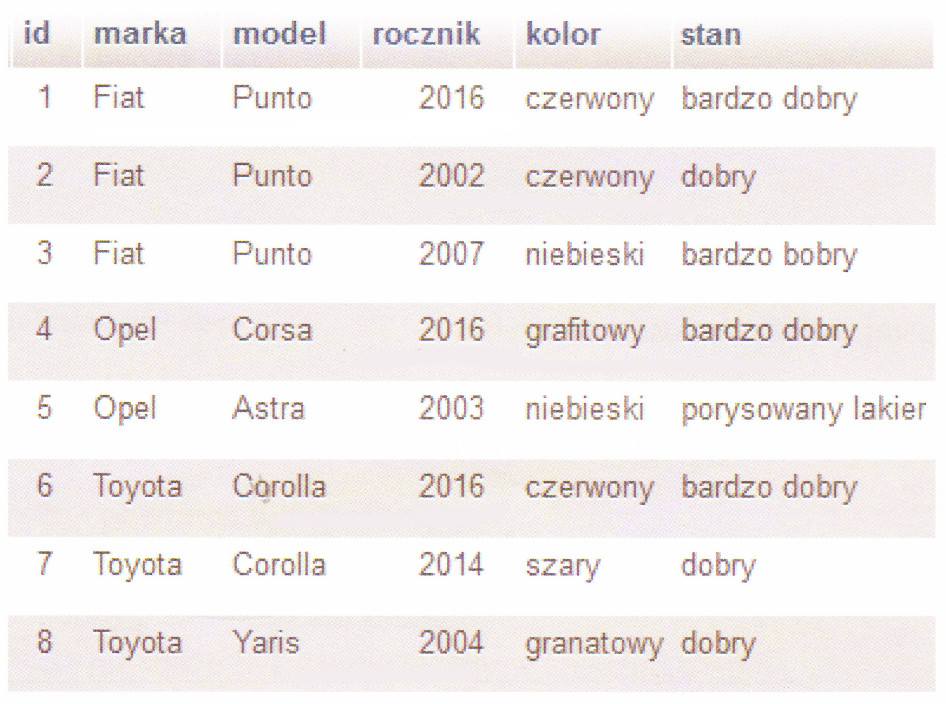
Jakie wartości zostaną wyświetlone przez funkcję wypisz(2) napisaną w języku JavaScript?

A. 3 4 6
B. 2 3 4 6
C. 3 4 6 8
D. 6
Funkcja wypisz w JavaScript działa w ten sposób, że przyjmuje argument a i korzysta z pętli for, która powtarza się pięć razy, zwiększając a o 1 w każdej iteracji. Potem sprawdza, czy a jest podzielne przez 2 lub 3, co znaczy, że liczba musi spełniać jeden z tych warunków, żeby być wypisaną. Kiedy zaczniemy z a=2, po pierwszym obiegu pętli a idzie na 3, a 3 spełnia warunek, więc zostaje wypisana. Potem mamy 4 (4 jest podzielne przez 2) i też jest wypisana, a następnie 5, która nie łapie się w warunek. A potem mamy 6, która już wchodzi, bo 6%2==0 i 6%3==0. W efekcie funkcja wypisuje liczby 3, 4 i 6, co zgadza się z poprawną odpowiedzią 3. Warto też dodać, że korzystanie z document.write jest już trochę passé i lepiej używać innych metod, jak innerHTML, bo to jest bardziej bezpieczne i zgodne z nowoczesnymi standardami webowymi. To pozwala na lepszą manipulację treścią strony, co jest na pewno lepsze w kontekście aplikacji dynamicznych.