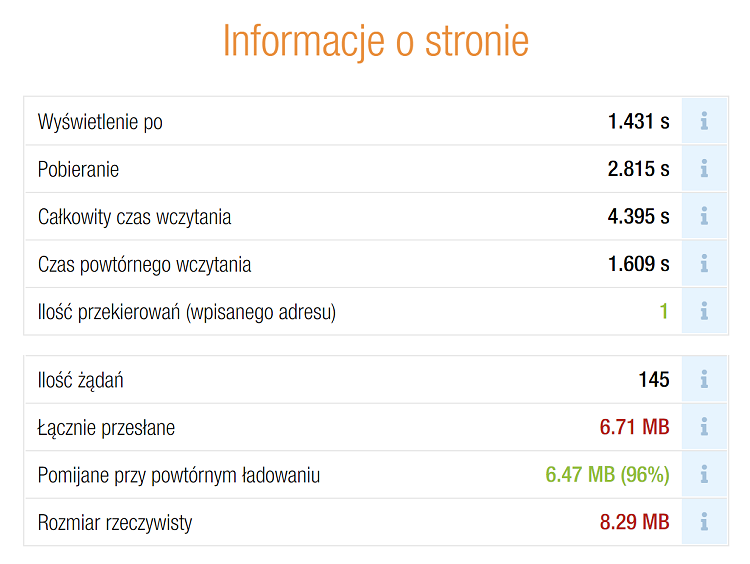
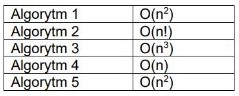
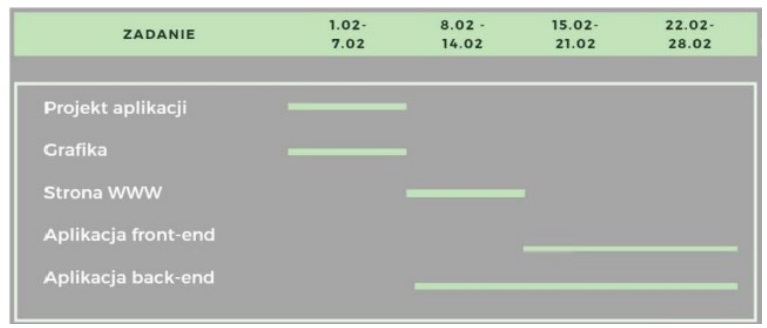
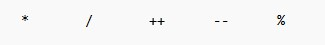Pytanie 1
Jaki jest kluczowy zamysł wzorca "Kompozyt" (Composite)?
A. Umożliwienie klientom obsługi obiektów oraz ich zbiorów w spójny sposób
B. Stworzenie jednej klasy do zarządzania wieloma obiektami tego samego rodzaju
C. Danie możliwości dynamicznej zmiany zachowania obiektu
D. Określenie interfejsu komunikacji pomiędzy składnikami systemu
Zarządzanie wieloma obiektami tego samego typu to cecha wzorca Fabryka (Factory) lub Builder, a nie Kompozyt. Definiowanie interfejsu komunikacji między komponentami systemu to rola wzorca Mediator, który organizuje interakcje między różnymi obiektami. Umożliwienie dynamicznej zmiany zachowania obiektu jest domeną wzorca Strategia (Strategy) lub Dekorator (Decorator), które oferują elastyczność w zakresie modyfikacji zachowania podczas działania programu.