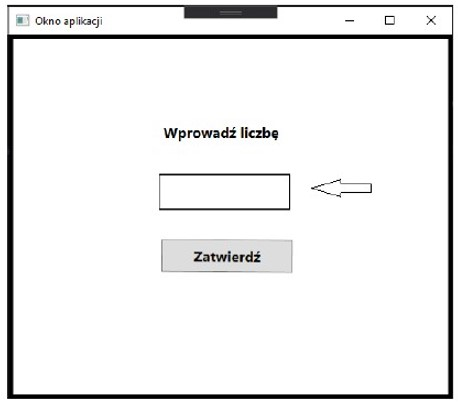
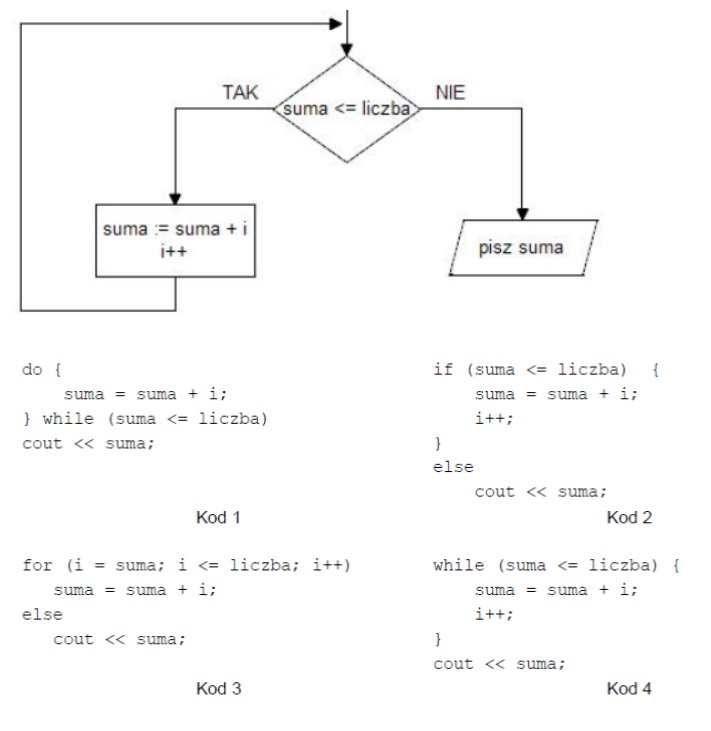
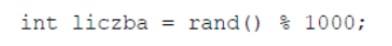Pytanie 1
Jakie polecenie w Gicie jest używane do zapisywania zmian w lokalnym repozytorium?
A. git push
B. git commit
C. git clone
D. git pull
Polecenie 'git commit' zapisuje zmiany w lokalnym repozytorium Git. Jest to kluczowy krok w procesie kontroli wersji, ponieważ każdy commit tworzy nową migawkę (snapshot) projektu, która może być w przyszłości przywrócona lub porównana z innymi wersjami. Polecenie to jest często używane razem z opcją -m, która umożliwia dodanie wiadomości opisującej zmiany. Dzięki temu możliwe jest efektywne śledzenie historii zmian w projekcie i przywracanie wcześniejszych wersji w razie potrzeby. Git commit to podstawowe narzędzie w pracy zespołowej nad kodem, szczególnie w środowisku deweloperskim, gdzie wersjonowanie jest niezbędne do zapewnienia stabilności kodu i łatwej współpracy.