Pytanie 1
Fragment kodu w języku HTML zawarty w ramce ilustruje zestawienie
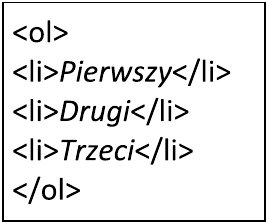
A. skrótów.
B. wypunktowaną.
C. numerowaną.
D. odnośników.
Znaczniki HTML
- i
- są często mylone przez początkujących deweloperów co prowadzi do nieporozumień związanych z prezentacją danych.
- reprezentuje listę wypunktowaną używaną gdy kolejność elementów nie ma znaczenia a celem jest po prostu grupowanie powiązanych elementów. Z kolei
- tworzy listę numerowaną co jest istotne gdy chronologia lub priorytet poszczególnych elementów są kluczowe. Struktura
- jest preferowana w dokumentach gdzie ważne jest zachowanie kolejności jak na przykład w instrukcjach krok po kroku lub w raportach podsumowujących. Mylenie tych dwóch znaczników może prowadzić do zamieszania w zrozumieniu prezentacji danych. Kolejną błędną interpretacją jest uznawanie list za odnośniki co jest domeną znacznika używanego do tworzenia hiperłączy między stronami. Jest to kluczowe w nawigacji strony i budowie struktury sieciowej. Z kolei skróty w HTML są reprezentowane za pomocą co pomaga w dostarczaniu pełnych form skrótów przy zachowaniu ich kompaktowej postaci w tekście. Poprawne rozróżnianie i stosowanie tych znaczników jest fundamentem dobrych praktyk w projektowaniu stron internetowych zgodnie z zasadami semantyki i dostępności co jest kluczowe dla tworzenia przejrzystych i przyjaznych użytkownikowi interfejsów. Dodatkowo przekłada się to na lepsze wyniki SEO oraz wyższy poziom użyteczności aplikacji webowych który jest coraz częściej oczekiwany na współczesnym rynku IT. Właściwe wykorzystanie semantycznych znaczników wpływa korzystnie na przyszłą konserwację i rozbudowę kodu co jest nieocenione w długoterminowych projektach informatycznych. Poprawne zrozumienie tych różnic jest zatem kluczowe dla każdego kto aspiruje do profesjonalnego tworzenia stron internetowych i aplikacji webowych zgodnie z nowoczesnymi standardami branżowymi.