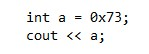Pytanie 1
Użycie typu DECIMAL w SQL wymaga wcześniejszego określenia liczby cyfr przed przecinkiem oraz ilości cyfr za przecinkiem. Jest to zapis:
A. logicznym
B. stałoprzecinkowy
C. zmiennoprzecinkowy
D. łańcuchowym
Typ DECIMAL w języku SQL to typ zmiennoprzecinkowy, który umożliwia przechowywanie liczb z określoną liczbą miejsc po przecinku. Jest szeroko stosowany w finansach i innych dziedzinach wymagających dużej precyzji, ponieważ unika błędów zaokrągleń, które mogą wystąpić przy użyciu typów FLOAT lub REAL. Przechowywanie danych liczbowych w dokładny sposób ma kluczowe znaczenie w aplikacjach związanych z walutami i statystyką.