Pytanie 1
Mamy tabelę firm, która zawiera takie kolumny jak: nazwa, adres, NIP, obrot (obrót w ostatnim miesiącu), rozliczenie, status. Wykonanie zapytania SQL SELECT spowoduje wyświetlenie
| SELECT nazwa, NIP FROM firmy WHERE obrot < 4000; |
A. wszystkie informacje o firmach, które w minionym miesiącu osiągnęły obrót poniżej 4000 zł
B. wszystkie dane o firmach, które w ostatnim miesiącu miały obrót na poziomie co najmniej 4000 zł
C. tylko nazwę i numer NIP przedsiębiorstw, które w poprzednim miesiącu miały obrót wynoszący przynajmniej 4000 zł
D. tylko nazwę i numer NIP przedsiębiorstw, które w ostatnim miesiącu miały obrót mniejszy niż 4000 zł
Prawidłowa odpowiedź odwołuje się do kwerendy SQL SELECT która wybiera jedynie kolumny nazwa oraz NIP z tabeli firmy pod warunkiem że kolumna obrot jest mniejsza niż 4000 Kwerenda ta jest przykład zastosowania filtracji danych w celu wyodrębnienia specyficznych informacji z bazy danych co jest kluczowe w analizie biznesowej Dzięki tej operacji można uzyskać listę firm które w ostatnim miesiącu osiągnęły niski obrót co może być istotne dla działów finansowych i marketingowych w celu identyfikacji klientów wymagających dodatkowego wsparcia Tego rodzaju selektywne przetwarzanie danych jest częścią codziennej pracy analityków danych oraz specjalistów od zarządzania relacjami z klientami W praktyce w infrastrukturze bazodanowej tego typu zapytania mogą być stosowane do generowania raportów okresowych lub alertów biznesowych Przy projektowaniu kwerend SQL ważne jest aby precyzyjnie określać które kolumny i wiersze danych są interesujące co nie tylko zwiększa efektywność zapytań ale także pozwala na lepsze zarządzanie zasobami serwera Dobra praktyka polega na optymalizacji zapytań w celu minimalizacji czasów odpowiedzi oraz obciążenia systemów bazodanowych co jest kluczowe dla utrzymania wydajności i niezawodności w dużych systemach informatycznych

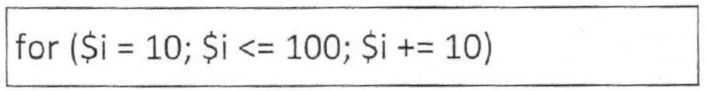
 tekst
tekst