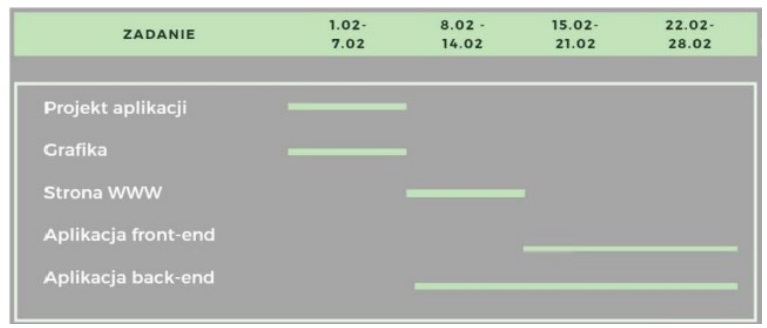
Pytanie 1
Celem mechanizmu obietnic (ang. promises) w języku JavaScript jest
A. zarządzanie przechwytywaniem błędów aplikacji
B. zastąpienie mechanizmu dziedziczenia w programowaniu obiektowym
C. ulepszenie czytelności kodu synchronicznego
D. zarządzanie funkcjonalnością związaną z kodem asynchronicznym
Mechanizm obietnic (Promises) w JavaScript umożliwia obsługę kodu asynchronicznego. Pozwala na efektywne zarządzanie operacjami, które mogą się zakończyć sukcesem lub błędem w przyszłości, np. pobieranie danych z API. Promisy umożliwiają unikanie tzw. 'callback hell' i poprawiają czytelność kodu.