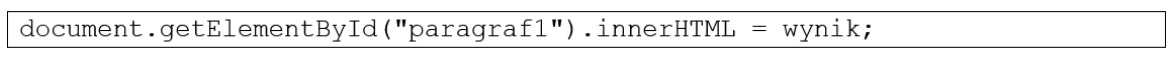Pytanie 1
Jednym z rodzajów testów jednostkowych jest badanie ścieżek, które polega na
A. stworzeniu kilku zbiorów danych o analogicznym sposobie przetwarzania i wykorzystaniu ich do przeprowadzenia testu
B. ustaleniu punktu startowego i końcowego oraz analizie możliwych tras pomiędzy tymi punktami
C. sprawdzaniu wartości granicznych zbioru danych
D. analizie obiektów pod kątem inicjalizacji oraz uwalniania pamięci
Istnieje wiele podejść do testowania jednostkowego, jednak nie każde z nich odnosi się do analizy ścieżek. Testowanie wartości brzegowych, które polega na sprawdzaniu skrajnych wartości danych wejściowych, jest istotnym procesem, ale nie jest to równoznaczne z analizą ścieżek. Wartości brzegowe koncentrują się na ekstremalnych przypadkach, a nie na logicznych ścieżkach, które kod może przyjąć, co sprawia, że jest to inne podejście do zapewnienia jakości oprogramowania. Kolejnym wynikiem nieporozumienia w kontekście analizy ścieżek jest testowanie obiektów pod kątem inicjacji i zwolnienia pamięci. To zagadnienie dotyczy zarządzania pamięcią, co jest innym aspektem testowania. Ważne jest, aby pamiętać, że analiza ścieżek koncentruje się na przepływie sterowania w programie, a nie na zarządzaniu pamięcią, które jest kluczowe, ale w zupełnie innym kontekście. Wreszcie, tworzenie zbiorów danych o podobnym sposobie przetwarzania i ich użycie do testów to technika, która również nie odnosi się bezpośrednio do analizy ścieżek, lecz do testowania danych. Problem z tym podejściem polega na tym, że niekoniecznie odzwierciedla ono złożoność logiki aplikacji i może prowadzić do pominięcia krytycznych ścieżek w kodzie. Zrozumienie różnicy pomiędzy tymi podejściami jest kluczowe dla skutecznego testowania oprogramowania.