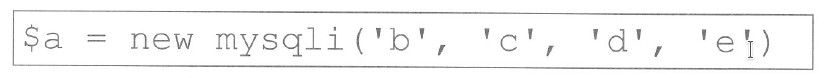Pytanie 1
Baza danych zawiera tabelę artykuły z kolumnami: nazwa, typ, producent, cena. Aby wypisać wszystkie nazwy artykułów jedynie typu pralka, których cena mieści się w zakresie od 1000 PLN do 1500 PLN, należy użyć zapytania
A. SELECT nazwa FROM artykuly WHERE typ="pralka" AND cena BETWEEN 1000 AND 1500
B. SELECT nazwa FROM artykuly WHERE typ="pralka" AND cena FROM 1000 TO 1500
C. SELECT nazwa FROM artykuly WHERE typ="pralka" OR cena BETWEEN 1000 AND 1500
D. SELECT nazwa FROM artykuly WHERE typ="pralka" OR cena BETWEEN 1000 OR 1500
Ta odpowiedź jest prawidłowa, ponieważ wykorzystuje polecenie SQL w odpowiedni sposób, aby wybrać nazwy artykułów, które spełniają określone kryteria. Słowo kluczowe 'BETWEEN' jest używane do określenia wartości w przedziale, co w tym przypadku oznacza, że cena artykułów musi mieścić się między 1000 a 1500 PLN. W połączeniu z warunkiem 'AND' zapewnia, że tylko te artykuły, które są typu 'pralka' i mają cenę w podanym przedziale, zostaną wyświetlone. W praktyce takie zapytanie jest niezwykle użyteczne w kontekście e-commerce, gdzie często przeprowadza się filtrowanie produktów według określonych parametrów. Dobrą praktyką w programowaniu SQL jest również używanie podwójnych cudzysłowów dla wartości tekstowych, co jest zgodne z niektórymi standardami SQL, chociaż w wielu systemach baz danych akceptowane są również pojedyncze cudzysłowy. Przykłady zastosowania tego zapytania można znaleźć w systemach zarządzania zapasami, gdzie potrzebne jest szybkie generowanie list produktów spełniających specyficzne wymagania klientów.
 jest poprawny niezależnie od kolejności atrybutów. Ważne jest, aby atrybuty były odpowiednio używane w kontekście ich przeznaczenia, a nie w kontekście kolejności alfabetycznej. Dobrą praktyką jest również stosowanie atrybutów w sposób, który zwiększa czytelność kodu, jednak nie jest to wymóg techniczny. Zgodnie z zaleceniami W3C, kluczowym aspektem jest poprawność semantyczna i zgodność ze standardami, a nie kolejność atrybutów.
jest poprawny niezależnie od kolejności atrybutów. Ważne jest, aby atrybuty były odpowiednio używane w kontekście ich przeznaczenia, a nie w kontekście kolejności alfabetycznej. Dobrą praktyką jest również stosowanie atrybutów w sposób, który zwiększa czytelność kodu, jednak nie jest to wymóg techniczny. Zgodnie z zaleceniami W3C, kluczowym aspektem jest poprawność semantyczna i zgodność ze standardami, a nie kolejność atrybutów.